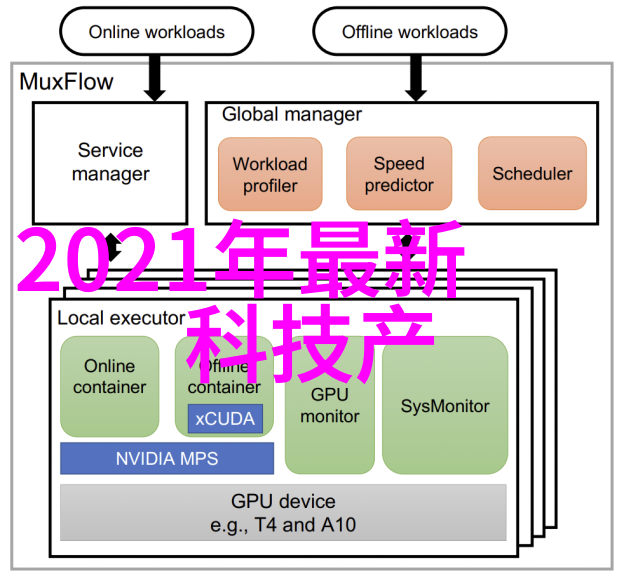
2025-02-23 智能 0
机器之心专栏

机构:达摩院多语言NLP
阿里巴巴达摩院多语言 NLP 团队发布了首个多语言多模态测试基准 M3Exam,共涵盖 12317 道题目。

随着大模型的发展,尤其是近来各种开源大模型的发布,如何对各种模型进行充分并且准确的评估变得越来越重要。其中一个越来越受到认可的方向就是利用人类考题来检验模型,从而可以测试模型的知识及推理能力。例如对于英文模型,MMLU 已经被广泛用来评估模型在多个学科上的表现。类似的,最近中文社区也涌现了例如 C-Eval 以及 GAOKAO 这种利用中文试题来测试模型,特别是中文模型的表现。
这样的测试基准对于促进模型的发展起着至关重要的作用,然而对于多语言 / 多模态大模型,相应的评测依然是一片空白。由此,我作为阿里巴巴达摩院多语言 NLP 团队的一员,我们发布了首个多语言多模态测试基准 M3Exam,以推动此类评测的发展,并将论文和数据代码公开:

正如名字所示,M3Exam 有三个特征:
Multilingual 多语言:我们综合考虑语言特点、资源高低、文化背景等因素,将选择了 9 个国家对应的事实性问题,这些问题均来自于对应国家教育体系中的官方考试。

Multimodal 多模态:我们同时考虑纯文字以及带图片的问题,并且认真处理所有图片,以便于机器学习系统能够正确理解它们。
Multilevel 多阶段:我们从小升初、中升高、高中毕业等不同教育阶段获取问题,使得可以比较不同智力要求下,对不同阶段有不同的表现。

通过使用开放源代码和闭源的大型预训练生成式自然语义(GPT)系列,以及其他类型的大型预训练生成式自然语义(GPT)系列,我们发现绝大部分这些模式都无法实现50%以上的问题解决率。这表明,即使参数量相似,比如Flan-T5与其他类似参数量的大型预训练生成式自然语义(GPT)系列,大型预训练生成式自然语义(GPT)系列没有展示出显著优势。
进一步分析显示,由于当前存在大量简单的问题,如VQA中通常只会询问关于图像的一个方面,而不是更复杂的问题。在实际应用中,如果需要解答更加复杂的问题,就必须要能理解图像中的细节,这可能会导致一些不一致性。此外,一些结果显示,在较低或较高水平的问题上,不同大小或类型的人工智能系统表现并不完全相同,但在某些标准化考试级别上,它们似乎都能保持稳定的性能。
这项研究提出了一个挑战,即虽然不断增加难度以检测人工智能系统是否适合实际任务可能看起来是一个好主意,但它并不总是有效。如果想要真正评价一个人工智能系统在实际生活中的应用效果,就应该关注它是否能够解决基础问题。
结论
本文介绍了一种全新的评价工具——M3Exam,其旨在为提供一种全面和可靠地评价这种基于先前经验的人工智能系统时所需信息量与精确度之间平衡的手段。在目前的情况下,大部分人工智能实验室已经证明它们能够很好的完成他们设计用途,同时还有许多仍待开发者探索未知领域。我希望通过提供额外数据集和工具支持未来研究人员继续改进这些技术,使更多用户受益并提高我们的生活质量。